Abstract
Long-term memory is essential for multimodal agents to build coherent experience, accumulate world knowledge, and achieve continual learning. However, constructing effective memory goes beyond memory module design and basic requirements such as accuracy and fidelity; the key challenge lies in determining what to memorize. Multimodal agents, such as embodied agents, continuously perceive, reason, and act in real or virtual environments, receiving an unbounded stream of multimodal observations. From this combinatorial explosion of information, an agent must selectively retain content that is relevant to its role in the environment and valuable for future tasks. To bridge this gap, we frame memory generation as a learnable memorization policy and introduce TaskMem (Task-focused Memorization Policy Learning), a reinforcement-learning-based framework that enables the policy to dynamically adjust its focus to the demands of real tasks encountered in the environment. TaskMem adopts a two-phase training paradigm: Phase One learns how to memorize by optimizing memory quality under fundamental fidelity requirements; Phase Two occurs after deployment, where the agent learns what to memorize by tuning an adapter on its base MLLM, using recent environment tasks to define a reward model that guides the memorization policy toward task-relevant content. To evaluate our approach, we reformulate VideoMME, EgoLife, and EgoTempo into streaming benchmarks that simulate a realistic setting in which an agent processes streaming observations and handles tasks arriving online. To isolate memory assessment, the questions must be answered using only the agent's memory, without access to raw video. Built on Qwen3-VL-30B-A3B, TaskMem improves VQA accuracy by 6.3%, 7.0%, and 5.3% on these benchmarks, respectively.
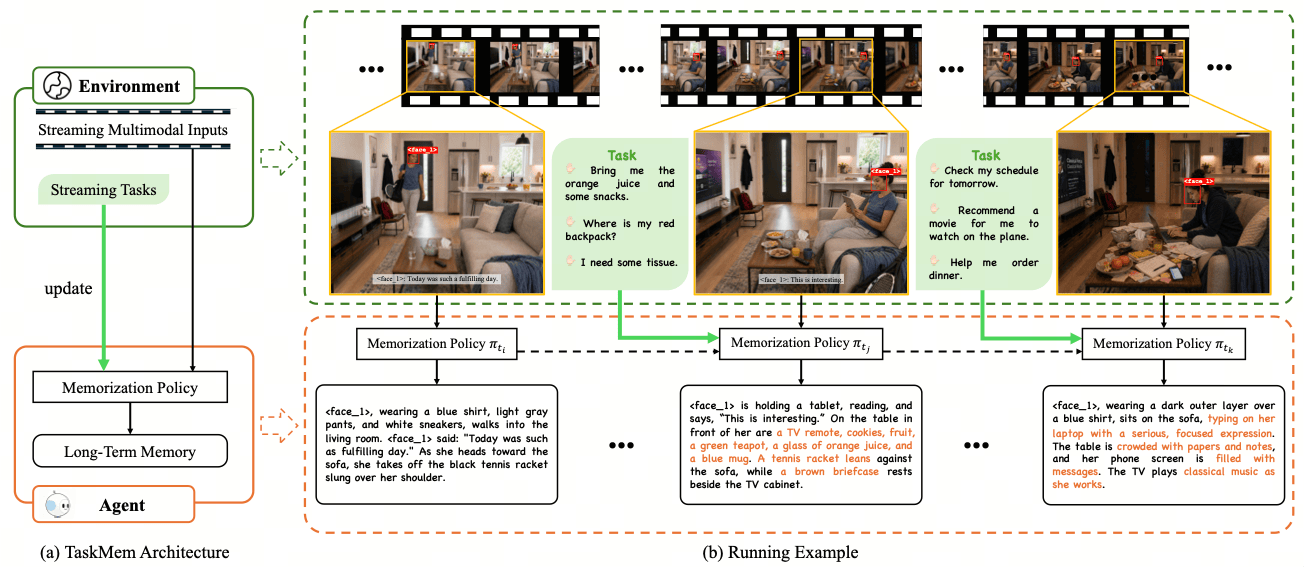
Method Overview
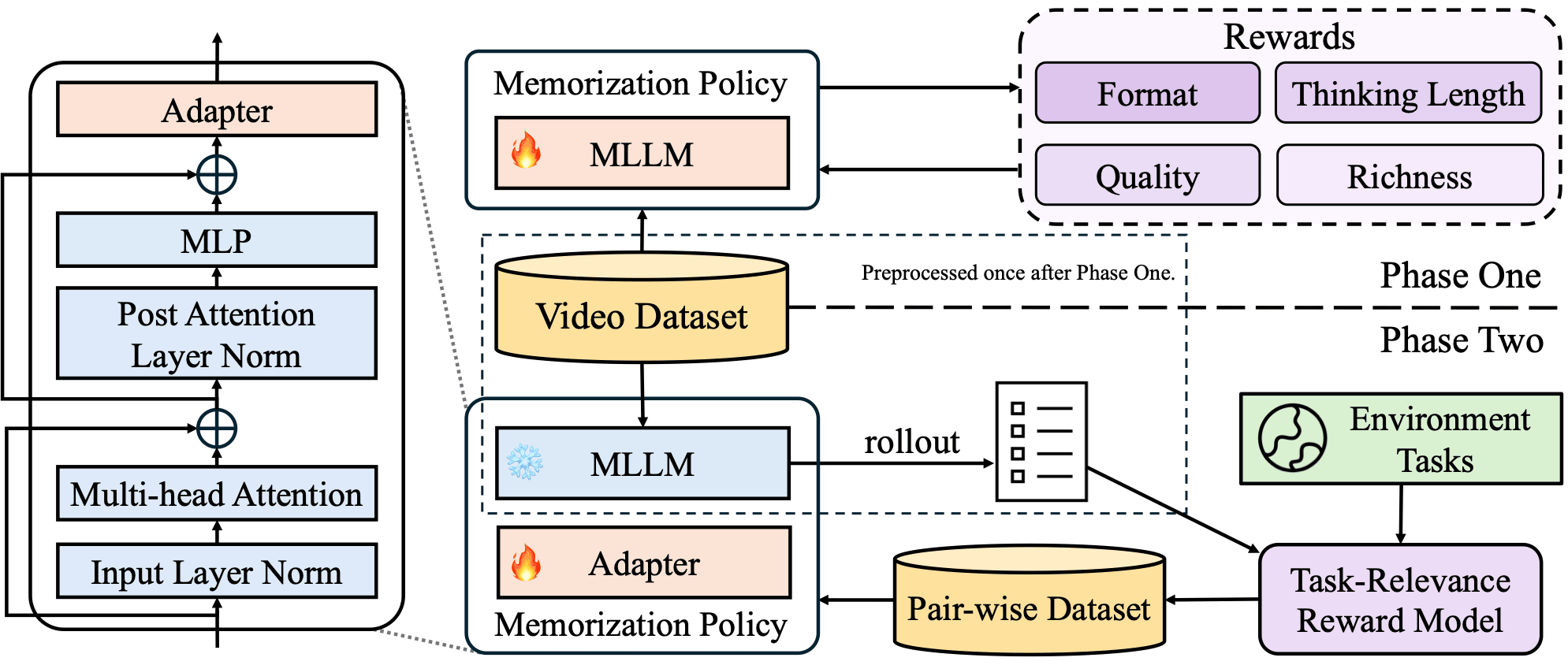
Two-phase training in TaskMem: Phase One optimizes the memorization policy for fundamental capabilities; Phase Two optimizes the policy to generate task-relevant content.
Main Results
Results on VideoMME, EgoLife, and EgoTempo. Best results are in bold, and second-best results are underlined.
| Method | VideoMME | EgoLife | EgoTempo | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Acc. (↑) | Cov. | Prec. (↑) | Acc. (↑) | Cov. | Prec. (↑) | Acc. (↑) | Cov. | Prec. (↑) | |
| EgoGPT | 44.3 | 58.7 | 75.5 | 19.2 | 28.2 | 68.1 | 15.0 | 33.5 | 44.9 |
| HippoMM | 48.9 | 66.6 | 73.5 | 30.4 | 43.4 | 70.0 | 15.8 | 30.8 | 51.1 |
| M3-Agent | 62.5 | 77.7 | 80.4 | 21.8 | 30.8 | 70.8 | 16.0 | 36.3 | 44.2 |
| Gemini-1.5-Pro | 55.3 | 65.9 | 83.9 | 39.4 | 51.6 | 76.4 | 19.7 | 34.3 | 57.4 |
| Gemini-2.5-Pro | 63.2 | 74.8 | 84.4 | 43.8 | 56.6 | 77.4 | 25.8 | 42.3 | 61.0 |
| GPT-5.2 | 67.3 | 80.8 | 83.3 | 34.8 | 48.2 | 72.2 | 32.1 | 51.4 | 62.4 |
| Qwen3-VL-30B-A3B | 61.6 | 74.7 | 82.5 | 38.4 | 52.4 | 73.3 | 22.3 | 38.9 | 57.2 |
| TaskMem (Ours) | 67.9 | 79.3 | 85.6 | 45.4 | 56.4 | 80.5 | 27.6 | 43.7 | 63.2 |
BibTeX
@article{zou2026taskmem,
title={Task-Focused Memorization for Multimodal Agents},
author={Zou, Tao and He, Yichen and Qiu, Tian and Lin, Yuan and Li, Hang},
year={2026}
}